In this analysis we’ll look at video updates sent with Buffer in 2019 and break them down by whether or not they were created by paying customers. The idea is to get a better sense of where our costs come from.
If a high percentage of video updates are sent by free users, resulting in a disproportionately high proportion of processing costs, it might make sense to only allow paying customers to create video updates.
Data Collection
We’ll collect video updates sent in 2019 from BigQuery.
# connect to BigQuery
con <- dbConnect(
bigrquery::bigquery(),
project = "buffer-data"
)
# define sql query
sql <- "
select
timestamp_trunc(up.created_at, month) as created_month
, u.billing_plan
, u.billing_plan_number
, count(distinct up.id) as video_updates
from dbt_buffer.publish_updates up
inner join dbt_buffer.publish_profiles p
on up.profile_id = p.id
inner join dbt_buffer.publish_users u
on p.user_id = u.id
where json_extract(up.media, '$.video') is not null
and up.synced_at >= '2019-01-01'
and up.created_at between '2019-01-01' and '2020-01-01'
group by 1,2,3
"
# query bigquery
videos <- dbGetQuery(con, sql)Now let’s plot the proportion of video updates that were sent by paying and free users across the year. It should be noted that we determine if a user is a paying customer by looking at their current plan.
That means that a user that sent a video update while on a paying plan in 2019 and later churned would not be considered a paying customer. Conversely, a user that sent a video update while on the Free plan in 2019 who later upgraded to a paid plan would be considered a paying customer in this plot.
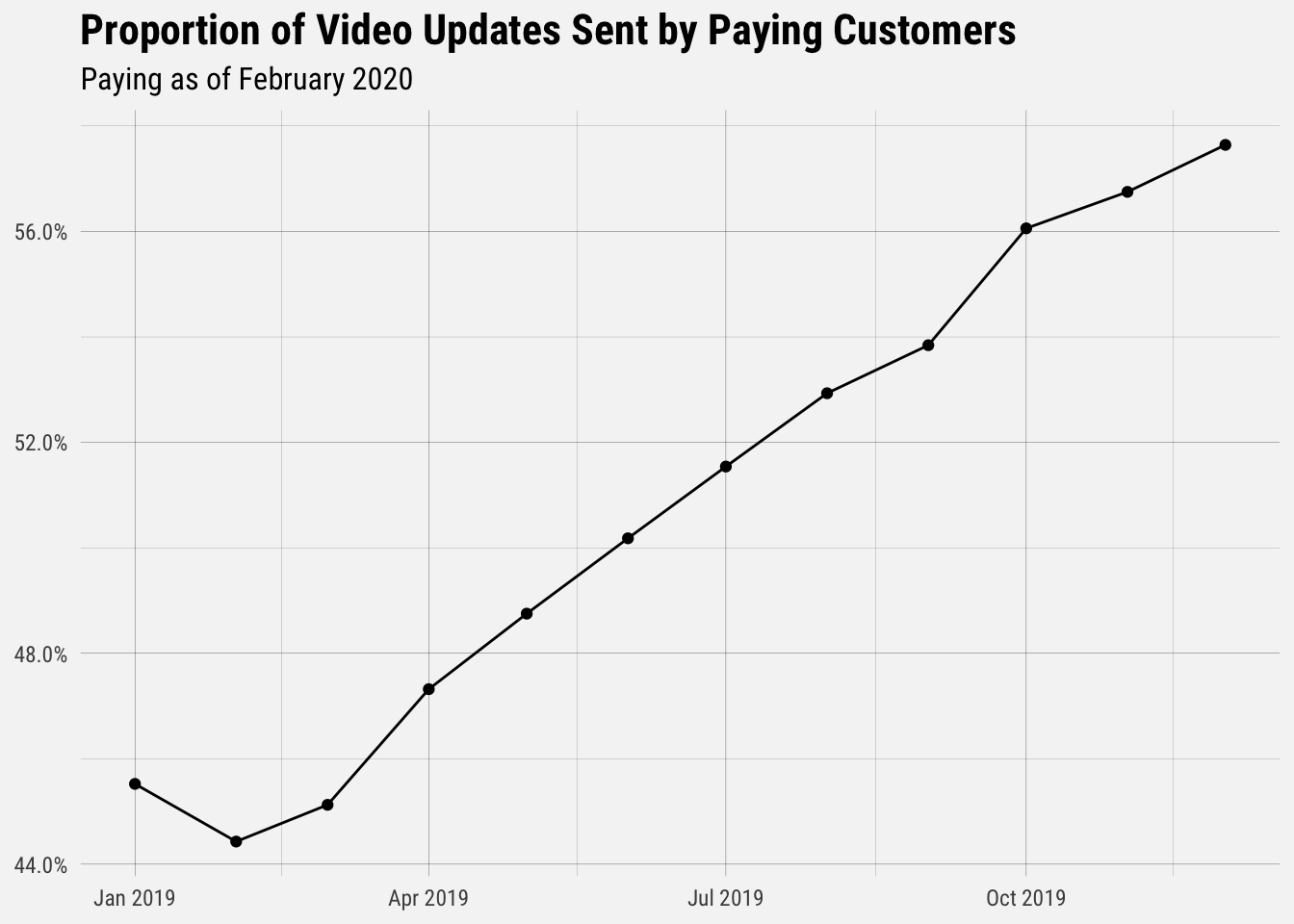
The proportion of video updates that were created by paying customers increased throughout 2019. This may be in part because we launched direct scheduling for Instagram videos. It may also be because we deemphasized the Free plan throughout the year.
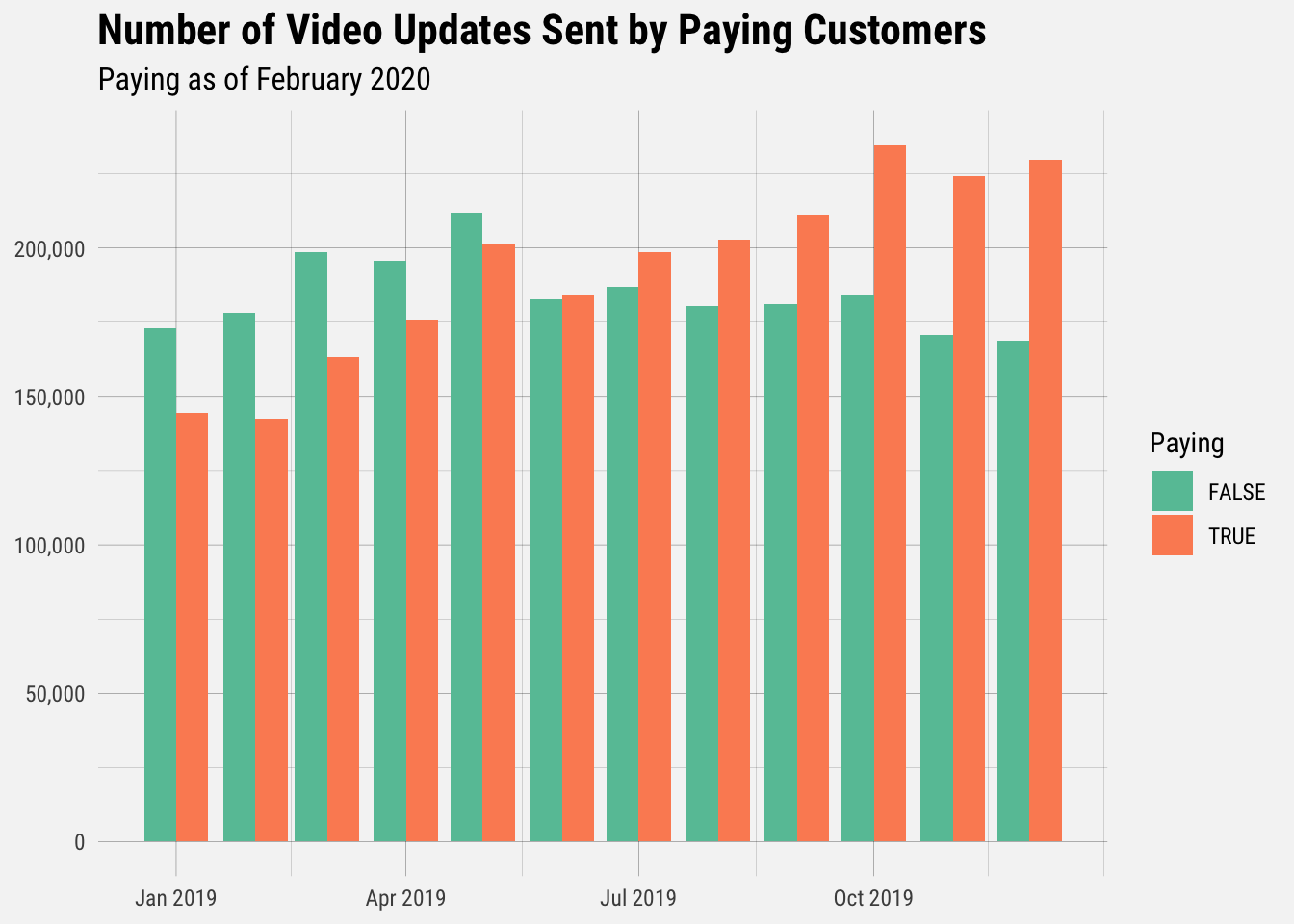
If we calculate the proportion of all video updates created in 2019 sent by users that are currently paying for Publish, it comes out to around 51%.
# get proportion of video updates for all of 2019
videos %>%
group_by(paying) %>%
summarise(videos = sum(video_updates)) %>%
mutate(prop = percent(videos / sum(videos)))## # A tibble: 2 x 3
## paying videos prop
## <lgl> <int> <chr>
## 1 FALSE 2212121 48.9%
## 2 TRUE 2313238 51.1%Who Shares the Most Video Updates
I’m assuming that the distribution of videos shared by user follows the power law distribution, with few users creating most of the videos, but let’s check and see if it’s true.
# connect to BigQuery
con <- dbConnect(
bigrquery::bigquery(),
project = "buffer-data"
)
# define sql query
sql <- "
select
u.id
, u.billing_plan
, u.billing_plan_number
, count(distinct up.id) as video_updates
from dbt_buffer.publish_updates up
inner join dbt_buffer.publish_profiles p
on up.profile_id = p.id
inner join dbt_buffer.publish_users u
on p.user_id = u.id
where json_extract(up.media, '$.video') is not null
and up.synced_at >= '2019-01-01'
and up.created_at between '2019-01-01' and '2020-01-01'
group by 1,2,3
"
# query bigquery
by_user <- dbGetQuery(con, sql)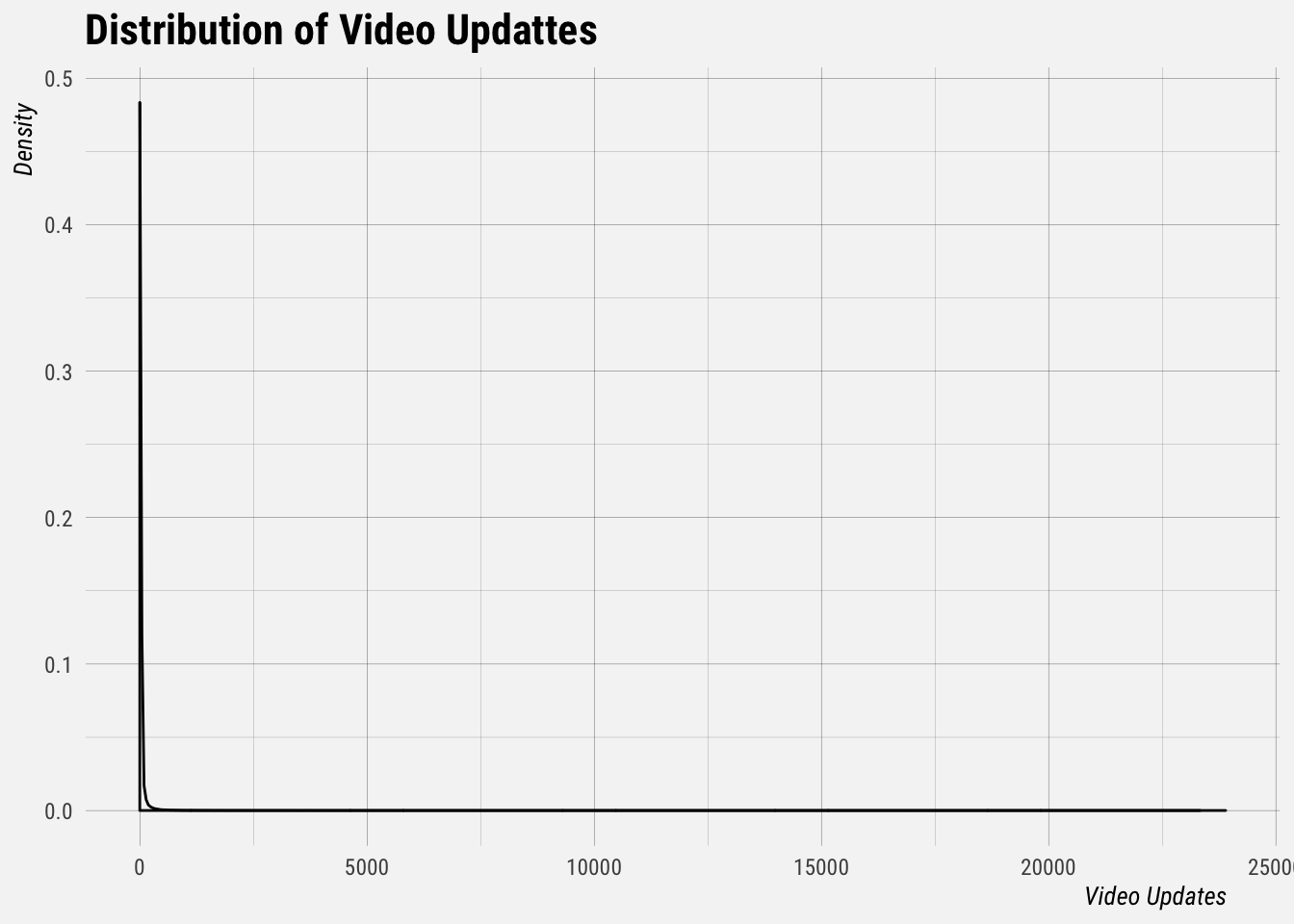
Yep, that’s a power law distribution. Let’s look at the top 25 users and see how many videos they sent.
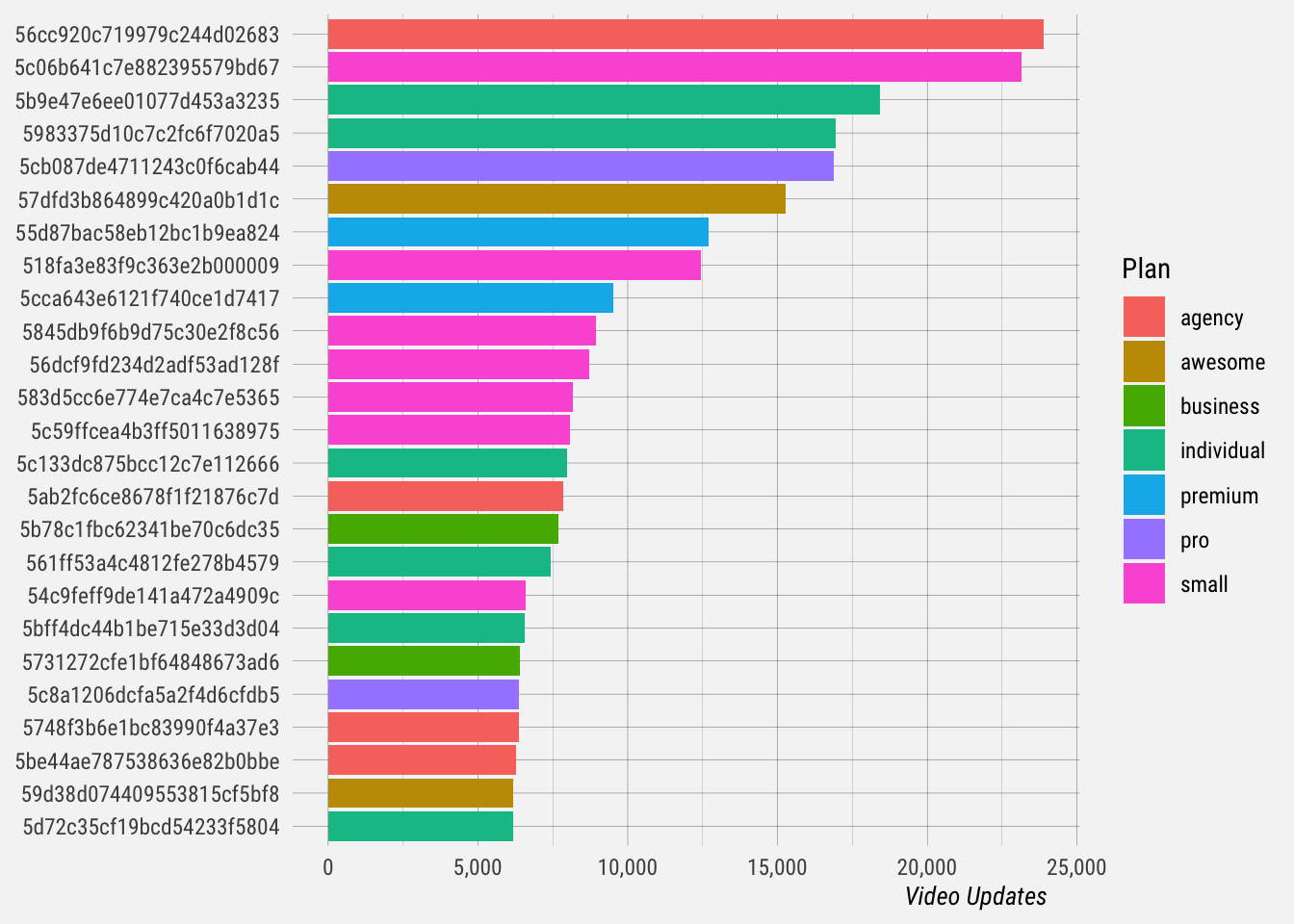
The top two users sent over 20 thousand video updates each, while the average for 2019 was 25 per user. The median was only 4 video updates per user.
summary(by_user$video_updates)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1.00 2.00 4.00 25.05 12.00 23896.00Now let’s determine if a user was sending an excessive amount of videos. We’ll define excessive as more than three standard deviations from the mean.
# calculate sd
mean(by_user$video_updates) + 3 * sd(by_user$video_updates)## [1] 576.972If a user sent more than 576 video updates in 2019, we’ll label them as “excessive”.
# count excessive users
by_user %>%
mutate(excessive = video_updates >= 577) %>%
count(excessive, name = "users") %>%
mutate(prop = percent(users / sum(users)))## # A tibble: 2 x 3
## excessive users prop
## <lgl> <int> <chr>
## 1 FALSE 179689 99%
## 2 TRUE 965 1%There were around 965 users sharing an excessive number of videos. They make up around 1% of the population of users that shared video updates in 2019.
# count videos sent by these users
by_user %>%
mutate(excessive = video_updates >= 577) %>%
group_by(excessive) %>%
summarise(videos = sum(video_updates)) %>%
mutate(prop = percent(videos / sum(videos)))## # A tibble: 2 x 3
## excessive videos prop
## <lgl> <int> <chr>
## 1 FALSE 3065709 68%
## 2 TRUE 1459650 32%This 1% of users sent 32% of all video updates in 2019. These are the users that shared the most video updates.
| id | billing_plan | video_updates |
|---|---|---|
| 56cc920c719979c244d02683 | agency | 23896 |
| 5c06b641c7e882395579bd67 | small | 23153 |
| 5b9e47e6ee01077d453a3235 | individual | 18415 |
| 5983375d10c7c2fc6f7020a5 | individual | 16935 |
| 5cb087de4711243c0f6cab44 | pro | 16882 |
| 57dfd3b864899c420a0b1d1c | awesome | 15270 |
| 55d87bac58eb12bc1b9ea824 | premium | 12712 |
| 518fa3e83f9c363e2b000009 | small | 12429 |
| 5cca643e6121f740ce1d7417 | premium | 9529 |
| 5845db9f6b9d75c30e2f8c56 | small | 8954 |
| 56dcf9fd234d2adf53ad128f | small | 8720 |
| 583d5cc6e774e7ca4c7e5365 | small | 8181 |
| 5c59ffcea4b3ff5011638975 | small | 8075 |
| 5c133dc875bcc12c7e112666 | individual | 7988 |
| 5ab2fc6ce8678f1f21876c7d | agency | 7856 |
| 5b78c1fbc62341be70c6dc35 | business | 7693 |
| 561ff53a4c4812fe278b4579 | individual | 7442 |
| 54c9feff9de141a472a4909c | small | 6586 |
| 5bff4dc44b1be715e33d3d04 | individual | 6567 |
| 5731272cfe1bf64848673ad6 | business | 6408 |
| 5c8a1206dcfa5a2f4d6cfdb5 | pro | 6362 |
| 5748f3b6e1bc83990f4a37e3 | agency | 6358 |
| 5be44ae787538636e82b0bbe | agency | 6262 |
| 59d38d074409553815cf5bf8 | awesome | 6185 |
| 5d72c35cf19bcd54233f5804 | individual | 6174 |
| 570f243131c2106c690883be | awesome | 5920 |
| 56d17fb7b1954e85720e3e56 | individual | 5890 |
| 594d523ba733306d159bc474 | pro | 5665 |
| 59c8fffcaa7cc06f27584dae | individual | 5569 |
| 5b5c545937d7ca7e61a5bd01 | agency | 5558 |
| 57d7c71fcde3fb437aff3be0 | pro | 5355 |
| 58e3dfc6c31add4b2906b033 | awesome | 5346 |
| 5abf76d4ed2d8f59482c22af | individual | 5336 |
| 501c21a4169f375402000008 | small | 5212 |
| 5c22a78ec7e882701a1cab09 | pro | 4943 |
| 5835fa7ef4b94a1b071770b4 | awesome | 4928 |
| 5b6ca6eee2d08d63152f927e | enterprise | 4836 |
| 5550e43e5f25329235e4fd1f | enterprise | 4722 |
| 58dc1439df8451697d43b8c6 | individual | 4663 |
| 592d0a62a9a493b701399549 | awesome | 4348 |
| 50e4cba71346afaa2a000004 | pro | 4325 |
| 5c73ee39e1896a2e825e0162 | enterprise | 4247 |
| 5238bd1eef17dcec1e000036 | awesome | 4241 |
| 5965c2b86bf29f2565ef5992 | small | 4155 |
| 5b76d0c03b2a39b42117aca8 | individual | 4154 |
| 5baa528bc7e882109c2dcb87 | individual | 4105 |
| 5abe44ee05fbf6c6511f1fe1 | individual | 4093 |
| 58ad727f7715cb29621d9a36 | small | 4060 |
| 5c6af86567358939ad1d3c63 | small | 3969 |
| 5af5a8084eca02c87f220664 | small | 3950 |
| 5bcce56fc7e8825a880d8f29 | individual | 3935 |
| 585f0ed7db0adaca6316d1ca | individual | 3850 |
| 5c84e3a48048ce1ecc1d6c44 | business | 3840 |
| 58b087eed7fd77d40eece837 | awesome | 3762 |
| 5a1cbd34936392440b0e9d6f | individual | 3741 |
| 5ca14616863f07454f3d0054 | individual | 3733 |
| 5c5cb5b7ea55276d1725d105 | individual | 3719 |
| 54c463adabdcfb425e8b4567 | agency | 3705 |
| 5aaab79be5f7cf5a7570a34c | individual | 3660 |
| 53b1b2f53a304e5d53e76352 | small | 3647 |
| 56c2db462ec27aa22c736957 | small | 3641 |
| 5bda464b93235d7ba471808c | business | 3609 |
| 4f0f037b512f7eea7f000008 | awesome | 3557 |
| 5c813c2f97226266aa60f815 | premium | 3436 |
| 5ba422904d496523b011e6a2 | small | 3419 |
| 56cf17fb5ddc69693a3b4116 | agency | 3393 |
| 5b03de32a21a1980071103dc | individual | 3370 |
| 5b7bcb4dbfdf6960466989c5 | small | 3366 |
| 5a82f477088690816a089c9a | awesome | 3316 |
| 593ebc8f840f27414bbdedc7 | individual | 3315 |
| 51ff4186ead9b81c0700000f | pro | 3298 |
| 589385af3b512a365dc4d291 | awesome | 3262 |
| 5c23f96187538654d80e4156 | pro | 3257 |
| 55efceaceaf59a6b223279ad | pro | 3218 |
| 572b124570a1d7de253797d0 | individual | 3203 |
| 5d4c1c9028de2b61e97f6907 | pro | 3203 |
| 5b4d0b9ce341a10f6650a12e | individual | 3199 |
| 5b0b4d9977bf97ae623c408a | individual | 3195 |
| 5936d634a9a493d4373f9229 | awesome | 3195 |
| 589295417fbcf55e6e8b8e84 | awesome | 3183 |
| 5b521109adaa83a13ecdcf60 | individual | 3147 |
| 5604879de80f06980b418c7b | individual | 3123 |
| 5b2cd827ecb246895bbc2b58 | individual | 3117 |
| 58b5b150a3454f8a28c1c745 | awesome | 3110 |
| 5c5d818bc84eee12526b0a24 | agency | 3087 |
| 51a9ad73ead9b88b43000007 | small | 3079 |
| 5d65f6eae56d174058612e32 | small | 3072 |
| 5bea4141d5bb024979408077 | small | 3060 |
| 5a7a902d69be2f82152d940a | agency | 3059 |
| 537a6bd9d1664c873f7b3f30 | agency | 2995 |
| 5be25722a32b5b3c0f7a69b4 | pro | 2977 |
| 59df7065513d8dc33bca1c75 | small | 2970 |
| 5b19cb391feda36a477ce6fc | individual | 2947 |
| 5ba251a03e4e157bb678ca12 | pro | 2897 |
| 5d336f3db94e34140540df68 | individual | 2880 |
| 5c4829644b1be71ae167b88c | individual | 2862 |
| 57cf0e1eeb331b1d307422fd | awesome | 2856 |
| 5421885b19b5425847a162ce | business | 2851 |
| 5885c9c331c2255d04c6dd09 | agency | 2850 |
| 582f0ac3fd827f2214f80dfb | pro | 2849 |